Logits and Softmax
Logits are the raw, unnormalized output scores of a language model for each token in the vocabulary, and the softmax function converts them into a valid probability distribution from which the next token is selected.
What Are Logits and Softmax?
Think of a language model as a judge scoring a talent competition with 50,000 contestants (tokens in the vocabulary). After processing the context, the model assigns each contestant a raw score – these are the logits. Some scores are high (likely next tokens), most are low (unlikely tokens), and some may be negative (very unlikely tokens).
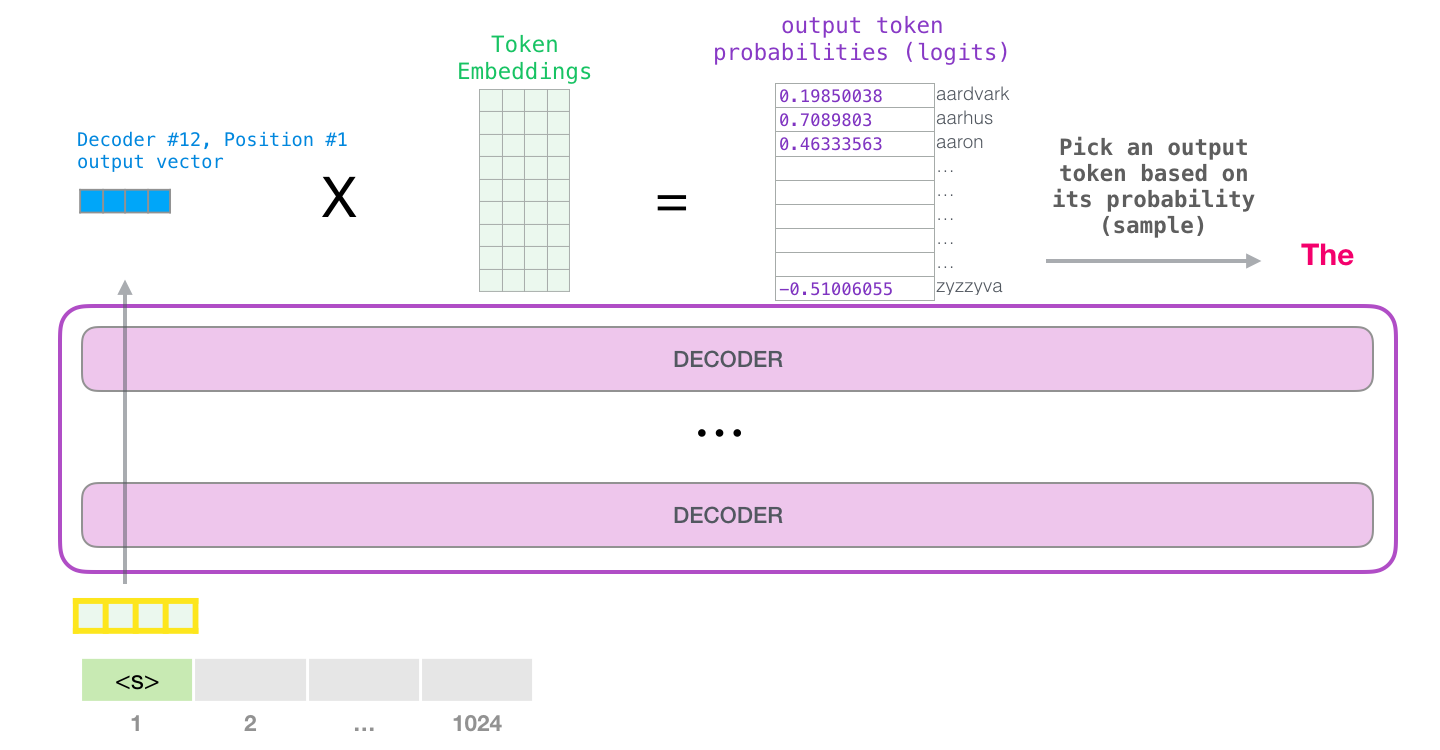
But raw scores are not probabilities. A score of 5.2 does not tell you “this token has a 30% chance.” To convert these raw scores into a proper probability distribution (non-negative values that sum to 1), we use the softmax function. After softmax, each token has a clear probability, and we can sample from this distribution to generate the next token.
The word “logit” comes from the logistic function and statistics. In the context of neural networks, it simply means “the output before the final activation (softmax).”
How It Works
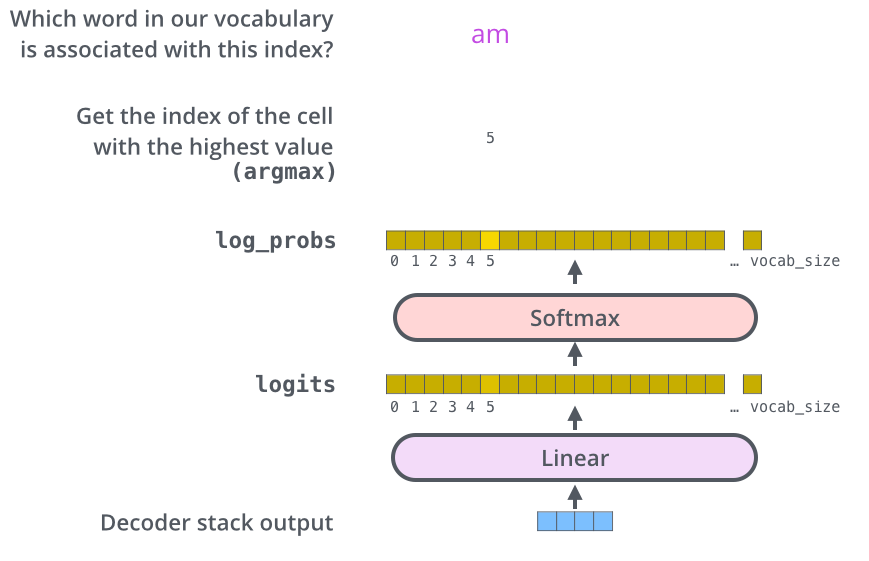
Step 1: The Language Model Head
After the final Transformer layer, each token position has a hidden state vector . To predict the next token, this hidden state is projected to a vector of size (the vocabulary size) using a linear layer:
where is the language model head weight matrix and is an optional bias. The output is the logits vector. Each element is the logit for vocabulary token .
Note: Most modern LLMs omit the bias , so the language model head is simply a matrix multiplication.
Step 2: Weight Tying
A widely used technique called weight tying (or shared embeddings) sets , meaning the language model head shares weights with the input embedding layer. This:
- Reduces parameter count by parameters (often 500M+ in large models).
- Creates a symmetric relationship: the embedding matrix maps tokens to vectors, and the same matrix (transposed) maps vectors back to token scores.
- Empirically improves performance, especially for smaller models. It acts as a regularizer by forcing the output space and input space to be aligned.
Not all models use weight tying. Some larger models (like certain LLaMA configurations) use separate embedding and head matrices, finding that the extra parameters improve quality at scale.
Step 3: Softmax
The softmax function converts logits into probabilities:
Properties of softmax:
- All outputs are positive: The exponential function ensures for all .
- Outputs sum to 1: The denominator normalizes the distribution.
- Preserves ordering: If , then .
- Amplifies differences: The exponential function makes large logits exponentially more likely than small ones. A difference of 1 in logit space becomes a factor of in probability space.
Step 4: Temperature Scaling
Before applying softmax, logits can be divided by a temperature parameter :
Temperature controls the “sharpness” of the distribution:
| Temperature | Effect | Distribution | Use Case |
|---|---|---|---|
| Approaches argmax (greedy) | Nearly all mass on top token | Deterministic, factual responses | |
| No change (default) | Model’s trained distribution | Balanced generation | |
| Flattens distribution | More uniform, more random | Creative, diverse generation | |
| Uniform distribution | All tokens equally likely | Pure randomness (useless) |
Numerical Stability
A practical implementation detail: computing directly can overflow for large logits. The standard trick is to subtract the maximum logit before exponentiation:
This is mathematically equivalent (the subtraction cancels in the ratio) but prevents overflow since the largest exponent is .
Why It Matters
The Bridge Between Representation and Generation
Logits and softmax are the critical interface between the model’s internal representations and the outside world. Everything the model has “learned” – all its knowledge, reasoning, and language understanding – is ultimately expressed as a logit vector. The entire training process (backpropagation through hundreds of billions of parameters) is driven by the loss computed at this layer.
Temperature and Creativity
Temperature is one of the most important user-facing parameters in LLM applications. The ability to control the randomness of generation through a single scalar is remarkably powerful:
- Code generation: Low temperature (0.0-0.3) for correctness.
- Creative writing: Higher temperature (0.7-1.0) for variety.
- Brainstorming: Even higher temperature (1.0-1.5) for diversity.
Understanding that temperature operates on logits before softmax explains why it works: it controls how much the model’s confidence differences translate into probability differences.
Log-Probability and Perplexity
The log of the softmax output () is the log-probability of a token. This is directly related to:
- Cross-entropy loss: The training objective is the negative average log-probability of the correct tokens.
- Perplexity: , a standard metric for language model quality. Lower perplexity means the model assigns higher probability to the correct tokens. A perplexity of 10 means the model is “as confused as if it were choosing between 10 equally likely options” on average.
Key Technical Details
- Vocabulary size: Typical values are 32,000 (LLaMA), 50,257 (GPT-2), 100,000+ (GPT-4, some multilingual models). The logits vector has this many dimensions.
- Language model head size: parameters. For and , that is ~131M parameters – significant but small relative to the full model.
- Log-softmax: In practice, implementations often compute directly using the log-sum-exp trick, which is more numerically stable than computing softmax and then taking the log.
- Logits are not bounded: Unlike probabilities (0 to 1), logits can be any real number: negative, zero, or positive. Their absolute values are not meaningful; only the relative differences matter.
- Top-k and top-p filtering: These decoding strategies operate on the sorted logits/probabilities, zeroing out low-probability tokens before sampling. They are applied after softmax (or equivalently, by masking logits before softmax).
- Logit bias: Some APIs allow adding a bias to specific token logits before softmax, which can be used to encourage or suppress particular tokens.
Common Misconceptions
- “Logits are probabilities.” Logits are raw scores that can be any real number, including negative. They must be passed through softmax to become probabilities.
- “A logit of 0 means the model has no opinion.” A logit of 0 means in the softmax numerator. Whether this translates to a high or low probability depends entirely on the other logits. If all logits are 0, every token gets equal probability.
- “Temperature 0 means the model is 100% confident.” Temperature 0 makes the sampling deterministic (always picks the argmax), but the model’s actual confidence (the probability assigned to the top token at ) might be low. Temperature controls sampling behavior, not model confidence.
- “The softmax output is the model’s ‘belief’ in each token.” Softmax probabilities are a mathematical convenience for training and sampling. They reflect the model’s output distribution, but interpreting them as calibrated beliefs or confidences requires additional calibration.
- “Weight tying always helps.” For very large models, untied weights can outperform tied weights because the input embedding and output prediction tasks may benefit from different representations. The tradeoff depends on model size and vocabulary size.
Connections to Other Concepts
- Next Token Prediction: The logits are the direct output that the next-token prediction loss is computed over (see Next Token Prediction).
- Autoregressive Generation: Token selection from the softmax distribution is the core of the generation loop (see Autoregressive Generation).
- Feed Forward Networks: The hidden state that becomes logits is the residual stream output, shaped heavily by FFN layers (see Feed Forward Networks).
- Activation Functions: Softmax is itself an activation function, applied at the final output layer (see Activation Functions).
- Transformer Architecture: The logits layer sits on top of the full Transformer stack (see Transformer Architecture).
Further Reading
- “On the Properties of Neural Machine Translation: Encoder-Decoder Approaches” – Cho et al., 2014 (early work on softmax in sequence-to-sequence models) [Scholar]
- “Using the Output Embedding to Improve Language Models” – Press and Wolf, 2017 (weight tying technique) [Scholar]
- “The Curious Case of Neural Text Degeneration” – Holtzman et al., 2020 (analysis of decoding strategies including temperature, top-k, and nucleus sampling) [Scholar]