Positional Encoding
Positional encoding injects information about token order into the transformer architecture, which would otherwise treat its input as an unordered set.
What Is Positional Encoding?
Consider this thought experiment: you hand someone a bag of Scrabble tiles spelling “THE DOG BIT THE MAN.” They can see every word, but the tiles are jumbled in the bag with no indication of order. They might reconstruct the sentence, or they might read “THE MAN BIT THE DOG” – a very different meaning from the same words.
This is exactly the problem transformers face. The self-attention mechanism computes relationships between all pairs of tokens simultaneously, with no inherent notion of sequence. Mathematically, if you shuffle the input tokens and correspondingly shuffle the attention outputs, you get the same result. This property is called permutation equivariance, and while it makes transformers highly parallelizable, it means they are blind to word order without explicit help.
Positional encoding is that help. It augments each token’s embedding with information about where the token sits in the sequence, allowing the model to distinguish “dog bites man” from “man bites dog.”
How It Works
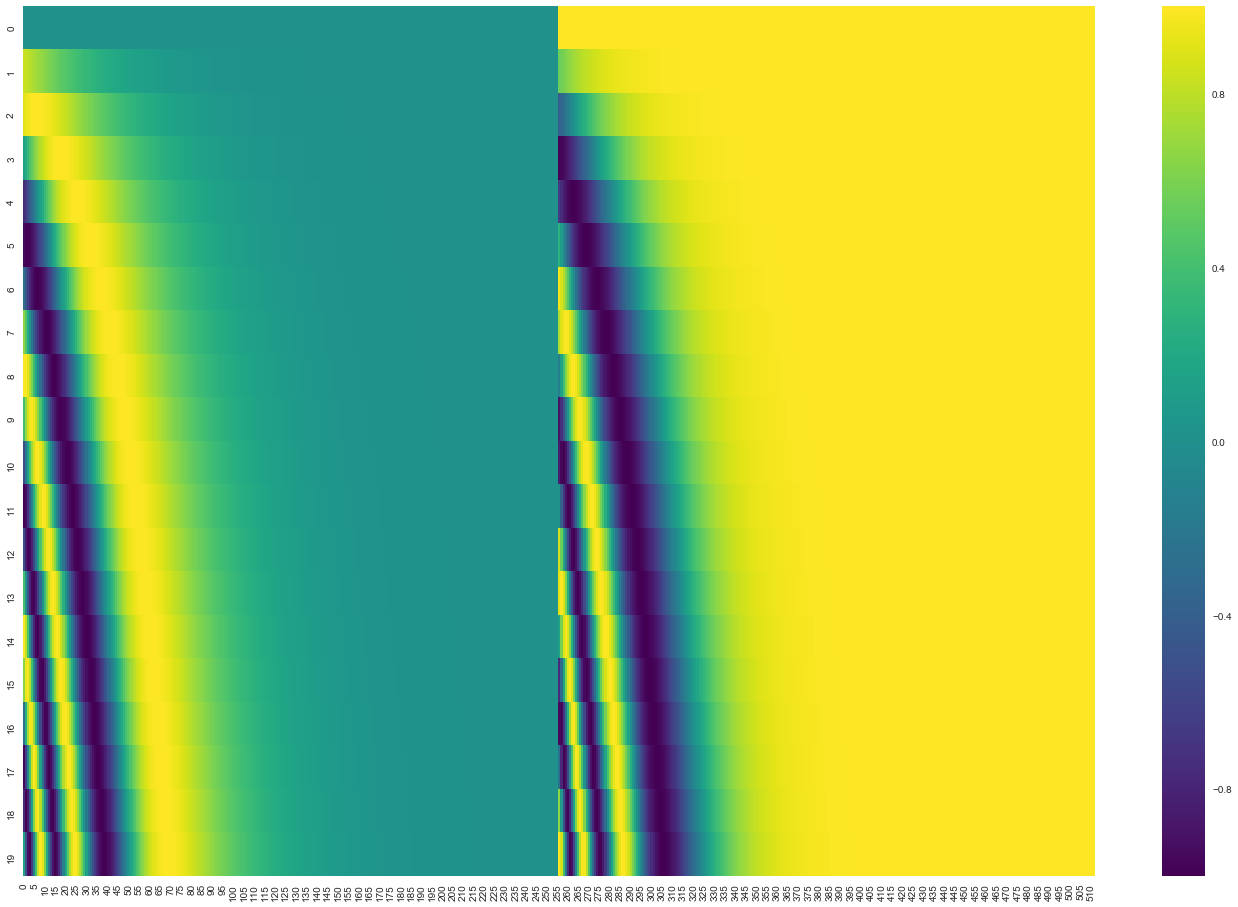
Sinusoidal Positional Encoding (The Original)
The original transformer paper (“Attention Is All You Need,” Vaswani et al., 2017) proposed injecting position using sine and cosine functions of different frequencies. For a token at position and embedding dimension :
where is the embedding dimension and ranges from to .
Why sinusoids? The key property is that the positional encoding for position can be expressed as a linear transformation of the encoding at position , for any fixed offset . This means:
This allows the model to learn to attend to relative positions through linear operations – attending to “the word 3 positions back” is a learnable linear function regardless of absolute position.
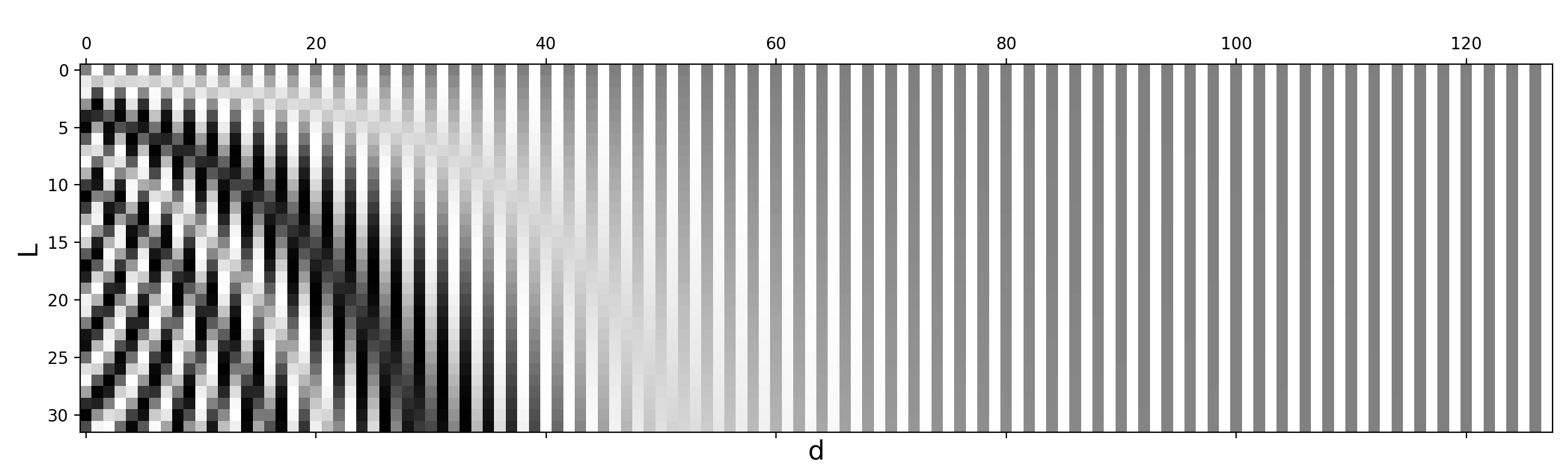
Each dimension of the positional encoding oscillates at a different frequency. Low-dimensional components have long wavelengths (varying slowly with position), encoding coarse position information. High-dimensional components have short wavelengths (varying rapidly), encoding fine-grained position.
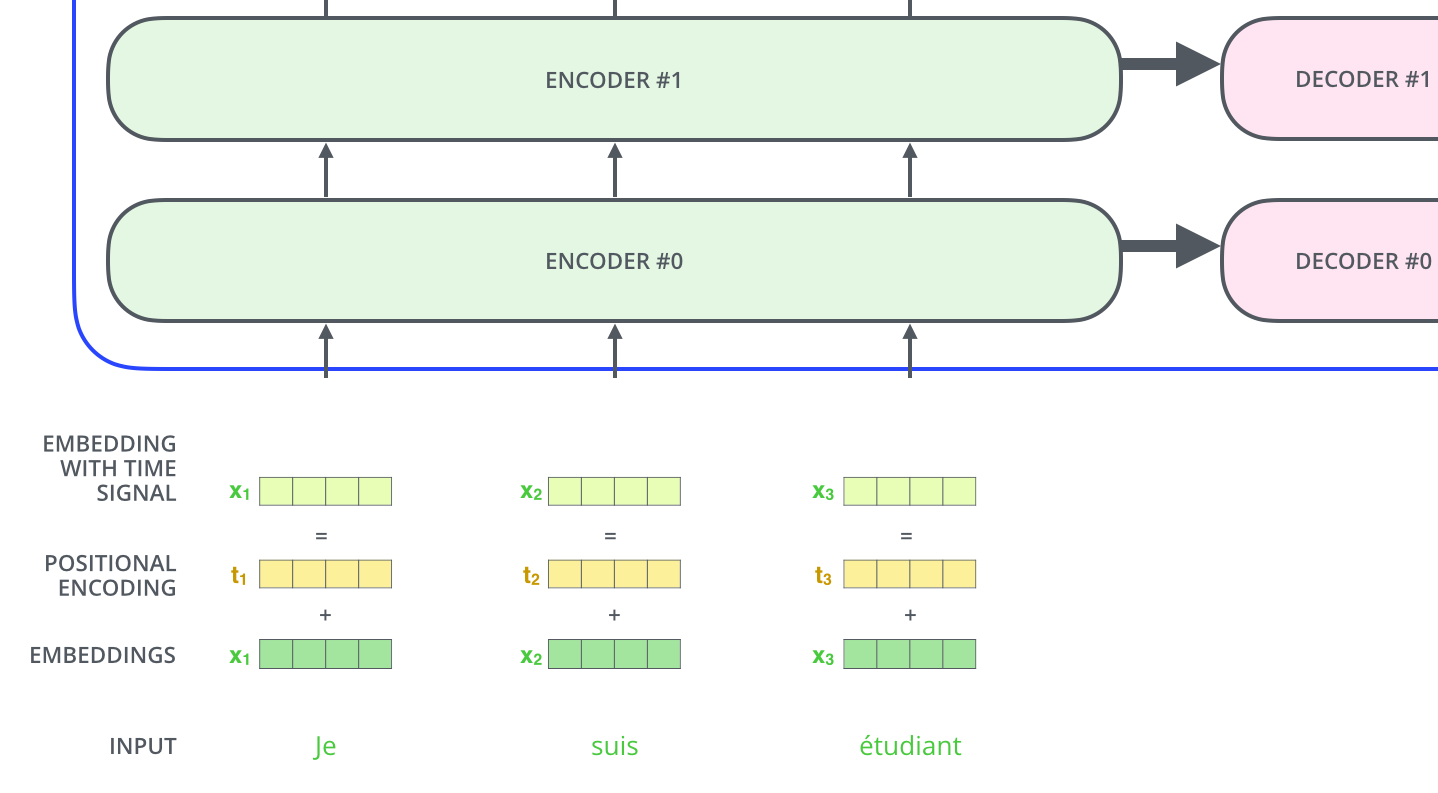
The positional encoding vector is added element-wise to the token embedding:
Learned Positional Embeddings
An alternative approach, used by GPT-2 and BERT, simply learns a positional embedding matrix , where is the maximum sequence length. Position is represented by row of this matrix, learned through backpropagation just like token embeddings.
This is simpler and often performs comparably for the training length, but has a hard limitation: is fixed at training time. The model has no embedding for position .
Absolute vs. Relative Position
Absolute positional encodings (both sinusoidal and learned) assign a unique representation to each position. The model must learn to extract relative position information from the difference between absolute positions.
Relative positional encodings directly encode the distance between tokens rather than their absolute positions. The key insight is that in language, relative position matters more than absolute position. Whether “quickly” modifies “ran” shouldn’t depend on whether they appear at positions (5, 6) or (50, 51).
Relative approaches include:
- Shaw et al. (2018): Added learnable relative position biases to attention scores.
- T5 Relative Bias: Uses a learned bias added to the attention logit between positions and . Positions are bucketed logarithmically so nearby positions are distinguished finely while distant positions are binned together.
- RoPE (Rotary Position Embedding): Encodes relative position through rotation of query and key vectors. Dominant in modern LLMs.
- ALiBi (Attention with Linear Biases): Adds a simple linear penalty to attention scores, with no learned parameters. Used by BLOOM and MPT.
The Evolution
The progression of positional encoding reflects the field’s growing understanding of what matters:
- 2017: Sinusoidal (fixed, absolute) – simple, elegant, but limited extrapolation.
- 2018-2019: Learned absolute (GPT-2, BERT) – more flexible, but fixed maximum length.
- 2020: Relative biases (T5) – better generalization across positions.
- 2021-2022: RoPE (LLaMA, PaLM) and ALiBi (BLOOM) – relative position in the attention computation itself, with better length generalization.
- 2023-2024: NTK-aware scaling, YaRN – extending context beyond training length by modifying RoPE.
Why It Matters
Without positional encoding, a transformer would be a “bag of words” model – powerful at understanding what concepts are present but unable to grasp syntax, narrative flow, logical argument structure, or code indentation. Consider:
- “The cat chased the mouse” vs. “The mouse chased the cat” – same tokens, opposite meaning.
- Code: Indentation and statement ordering are essential for semantics.
- Mathematics: “2 + 3 = 5” vs. “3 + 2 = 5” are both valid, but “5 = 2 + 3” is a different statement.
The choice of positional encoding method also determines whether a model can handle sequences longer than it was trained on. This is the length extrapolation problem, which has driven the evolution from absolute to relative approaches and enabled the expansion of context windows from 512 tokens (BERT) to millions (Gemini 1.5).
Key Technical Details
- Positional encodings are added to, not concatenated with, token embeddings. Addition preserves dimensionality but means token identity and position share the same representational space.
- In multi-layer transformers, position information is injected once at the input layer (for absolute methods) or at every attention layer (for relative methods like RoPE and ALiBi). Applying position at every layer is part of why RoPE works so well – position information doesn’t have to survive degradation through many layers.
- Sinusoidal encodings have a maximum theoretical period of for the lowest-frequency dimension, providing a natural (but approximate) length limit.
- ALiBi uses no learned parameters at all – just fixed linear slopes. Despite its simplicity, it showed competitive performance and good extrapolation, demonstrating that positional encoding need not be complex.
- The attention score between positions and in a standard transformer is . Relative methods modify this to include position: e.g., RoPE computes , making it a function of the distance .
Common Misconceptions
- “Transformers have no concept of order.” Incorrect – with positional encodings, they do. The correct statement is that the attention mechanism alone is permutation equivariant; positional encoding breaks this symmetry.
- “Sinusoidal encoding can handle any length.” While theoretically defined for any position, models trained with sinusoidal encoding at length 512 degrade significantly at length 1024. The model has never learned attention patterns for those position combinations.
- “Adding position to token embeddings destroys token information.” It does create interference, but the model learns to use the combined signal effectively. Some architectures (notably, some vision transformers) have explored concatenation as an alternative, but addition works well in practice and is parameter-free.
- “Relative position encoding is always better than absolute.” For short, fixed-length tasks, absolute encodings work perfectly well. Relative encodings shine for length generalization and tasks where distance matters more than absolute position.
Connections to Other Concepts
- Token Embeddings: Positional encodings are combined with token embeddings to form the input to the first transformer layer.
- Rotary Position Embedding: The dominant modern positional encoding method, deserving its own deep dive.
- Context Window: The maximum effective context length is heavily influenced by the positional encoding scheme and its ability to extrapolate.
- Self Attention: Positional encoding modifies what the attention mechanism “sees” about token relationships.
- Special Tokens: Tokens like BOS always appear at position 0, creating a consistent positional anchor.
Further Reading
- Vaswani, A., et al. (2017). “Attention Is All You Need.” NeurIPS 2017. – Introduced sinusoidal positional encoding alongside the transformer architecture. [Scholar]
- Su, J., et al. (2021). “RoFormer: Enhanced Transformer with Rotary Position Embedding.” arXiv:2104.09864. – Proposed RoPE, now the dominant approach in modern LLMs. [arXiv]
- Press, O., Smith, N.A., & Lewis, M. (2022). “Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation.” ICLR 2022. – Introduced ALiBi and rigorously studied length extrapolation. [Scholar]